



Dans l’ère numérique actuelle, le contenu est roi. Les éditeurs investissent un temps et des ressources significatives dans la création de contenu de haute qualité pour leurs audiences. Cependant, avec la montée en puissance de l’intelligence artificielle (IA), un nouveau défi a émergé : les robots et crawlers IA, ou bots, peuvent extraire le contenu des sites web et l’utiliser pour entraîner des modèles de langage de grande taille (LLM) qui imitent le langage humain. Cette pratique pose des problèmes de violation des droits d’auteur et soulève des inquiétudes quant à la concurrence entre le contenu original et le contenu généré par l’IA.
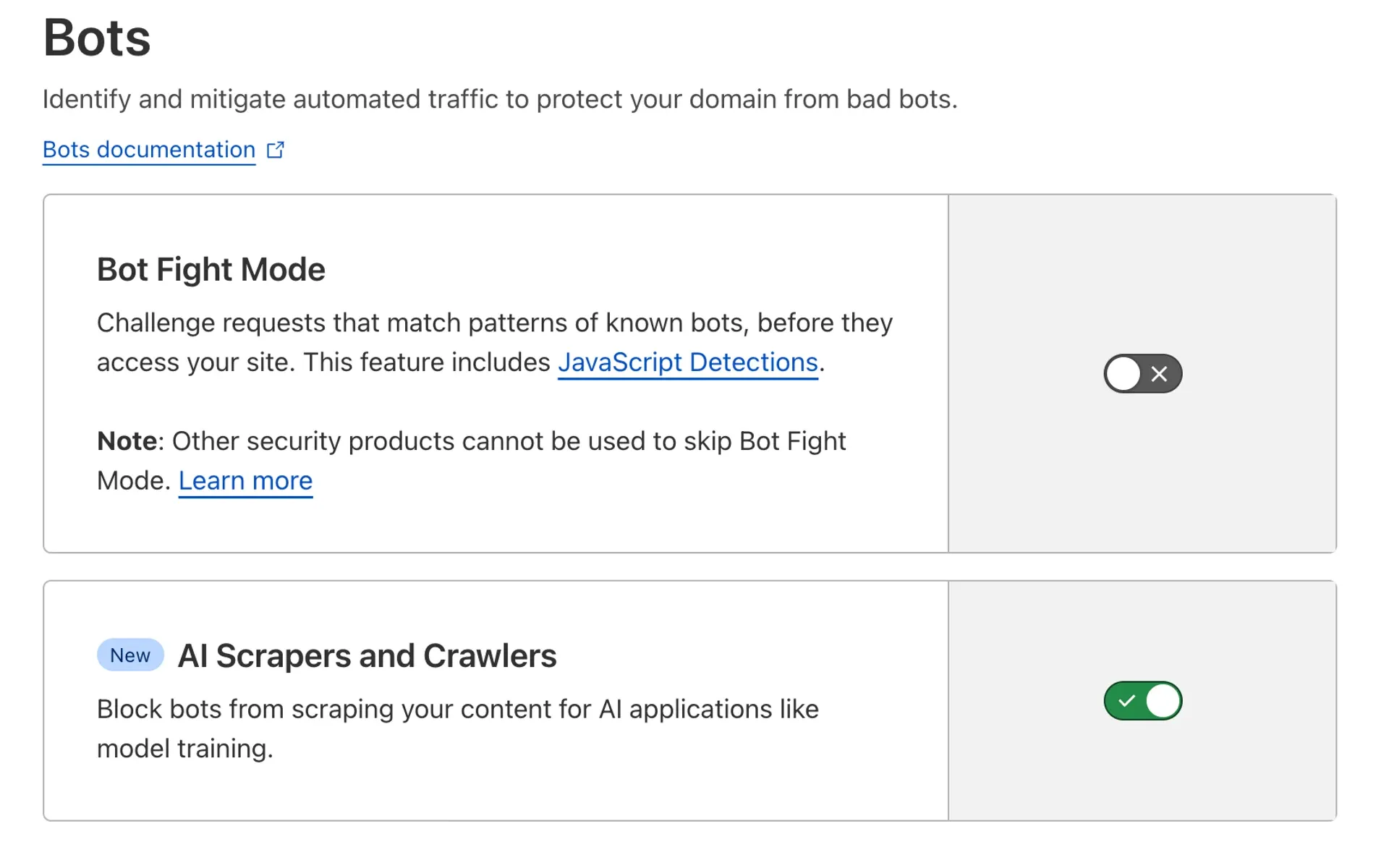
Cloudflare, un géant de la sécurité web, a récemment lancé une nouvelle fonctionnalité visant à contrer ce problème. Cette fonctionnalité offre aux éditeurs de sites web la possibilité de bloquer les robots IA non autorisés qui tentent de scraper leur contenu. En activant cette fonctionnalité via le tableau de bord Cloudflare, les éditeurs peuvent créer des règles personnalisées pour identifier et bloquer les bots IA. Cette innovation permet aux éditeurs de :
- Protéger la propriété intellectuelle : sauvegarder leur contenu unique contre une utilisation non autorisée pour l’entraînement des LLM.
- Maintenir l’exclusivité du contenu : s’assurer que leur contenu reste exclusif à leur plateforme, augmentant potentiellement la fidélité des lecteurs.
- Mieux monétiser le contenu : en contrôlant l’accès à leur contenu, les éditeurs peuvent explorer de nouvelles voies de monétisation.
Contrôle Granulaire des Bots
Cette mise à jour va au-delà du simple blocage des bots IA. Cloudflare propose également des « catégories de bots vérifiés », permettant aux éditeurs de prendre des décisions éclairées. Ils peuvent choisir de bloquer certains crawlers IA tout en autorisant d’autres qui opèrent de manière transparente et respectent les directives des sites web. Ce contrôle granulaire permet aux éditeurs de :
- Identifier les bons acteurs : distinguer entre les crawlers IA responsables et ceux ayant des intentions malveillantes.
- Permettre les crawlers bénéfiques : autoriser l’accès aux crawlers IA qui contribuent à la visibilité du site web ou au SEO.
- Définir des niveaux d’accès : établir différents niveaux d’accès pour diverses catégories de crawlers IA.
Bien que la solution de Cloudflare dote les éditeurs d’outils puissants, l’entreprise reconnaît la nécessité d’une collaboration à l’échelle de l’industrie. Ils plaident pour un protocole standardisé conçu spécifiquement pour gérer les crawlers IA. Cela fournirait aux éditeurs un cadre cohérent pour gérer l’accès au contenu IA sur l’ensemble du web.
Les nouvelles fonctionnalités de Cloudflare donnent aux propriétaires de sites web plus de contrôle pour bloquer les scrapeurs de contenu IA, mais la question sous-jacente des droits d’auteur et des données d’entraînement des LLM est complexe. Bien que cela offre plus de contrôle aux éditeurs, des questions légales et éthiques demeurent.
Les limites des solutions simples comme le fichier robots.txt
Modifier les fichiers robots.txt permet aux éditeurs de demander l’exclusion du scraping par des entreprises spécifiques d’IA (actuellement Google et OpenAI), mais ce n’est pas une solution infaillible. Cela ne garantit pas la conformité des autres entreprises et n’aborde pas le problème plus large des droits d’auteur et de l’usage équitable à l’ère de l’IA.
Mustafa Suleyman, PDG de Microsoft AI, soutient que la plupart des contenus web sont essentiellement des « freeware » pour l’entraînement de l’IA, sauf s’ils sont explicitement restreints. Cette perspective remet en question le concept de droits d’auteur et inquiète les éditeurs qui investissent des ressources substantielles dans la création de contenu unique.
L’enquête sur Perplexity, une startup de recherche IA, ajoute de l’huile sur le feu. Perplexity est accusée d’avoir scraped du contenu de sites web ayant explicitement bloqué l’accès via robots.txt, ce qui met en lumière le potentiel de mauvaise utilisation des pratiques de scraping dans l’entraînement des LLM.
Cette problématique va au-delà de la simple protection du contenu. Les pratiques de scraping non éthiques peuvent conduire à des données d’entraînement biaisées pour les LLM, impactant potentiellement l’exactitude et l’équité de ces modèles IA. À mesure que l’IA continue d’évoluer, la collaboration entre les décideurs politiques, les développeurs d’IA et les créateurs de contenu est cruciale pour établir un cadre qui favorise l’innovation tout en respectant les droits de propriété intellectuelle.





