



Émergence des bloqueurs de crawlers AI
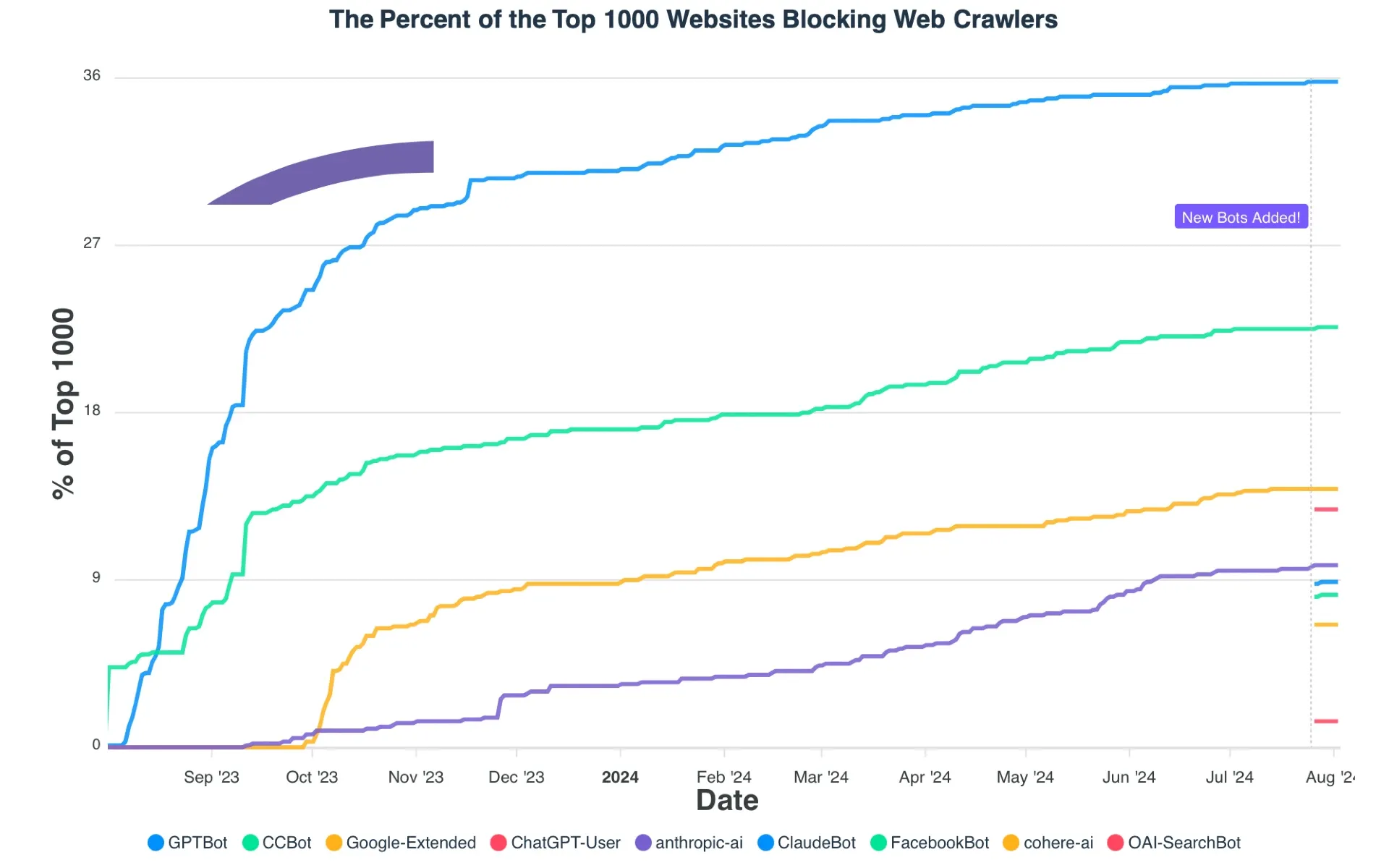
Le 3 août 2024, de nouvelles données ont révélé que plus de 35 % des 1000 meilleurs sites Web dans le monde bloquent désormais le crawler Web GPTBot d’OpenAI, marquant une augmentation significative des efforts pour restreindre les entreprises d’IA de scrapper du contenu en ligne. L’étude, menée par la société de détection d’IA Originality.AI, montre un paysage complexe de la manière dont les principaux sites Web réagissent à l’essor des modèles de langage étendu et des moteurs de recherche alimentés par l’IA.
La recherche, qui a analysé les fichiers robots.txt des 1000 principaux sites Web mondiaux, a révélé que GPTBot est désormais bloqué par 35,7% des sites, contre seulement 5% lorsqu’il a été introduit en août 2023. Cela représente une augmentation septuple des blocages au cours de l’année écoulée, reflétant les préoccupations croissantes concernant l’utilisation des contenus Web scrappés par les entreprises d’IA pour entraîner leurs modèles.
Autres crawlers AI également impactés
Selon les données, d’autres crawlers Web liés à l’IA font également face à des restrictions croissantes, bien que dans une moindre mesure que GPTBot. Le Common Crawl Bot (CCBot) est bloqué par 22,1% des principaux sites, Google-Extended par 13,6%, et ChatGPT-User par 12,7%. Les nouvelles entrées comme anthropic-ai, ClaudeBot et OAI-SearchBot sont bloquées à des taux variant entre 1% et 10%.
La montée des blocages a commencé peu après l’annonce par OpenAI de GPTBot le 7 août 2023. En l’espace de deux semaines, des sites majeurs comme Amazon, Quora, The New York Times et CNN avaient mis en place des blocages. La tendance s’est accélérée au cours de l’année écoulée, avec des taux de blocage augmentant régulièrement chaque mois.
Méfiance accrue des éditeurs de contenu
Plus particulièrement, de grands éditeurs de médias et de nouvelles bloquent maintenant GPTBot, y compris The New York Times, The Guardian, CNN, USA Today, Reuters, The Washington Post, NPR, CBS, NBC, Bloomberg et CNBC. Cela suggère une inquiétude particulière dans le secteur du journalisme concernant les systèmes d’IA qui pourraient potentiellement reproduire leur contenu.
Débats et ramifications légales
L’augmentation des blocages des crawlers survient au milieu de débats plus larges sur l’utilisation des données en ligne par les entreprises d’IA. En juillet 2024, il y a seulement deux semaines, OpenAI a annoncé un nouveau moteur de recherche alimenté par l’IA appelé SearchGPT, ainsi qu’un nouveau crawler nommé OAI-SearchBot. OpenAI affirme que ce nouveau crawler est uniquement utilisé pour faire apparaître des sites Web dans les résultats de recherche, et non pour entraîner des modèles d’IA.
Cependant, malgré ces assurances, 14 grands éditeurs, dont The New York Times, Wired, The New Yorker et Vogue, ont immédiatement bloqué OAI-SearchBot, se retirant ainsi des résultats de SearchGPT. Cette réaction rapide indique une méfiance persistante entre les éditeurs de contenu et les entreprises d’IA.
Motivations des entreprises pour les blocages
Les motivations pour bloquer les crawlers d’IA sont multiples. Certaines entreprises évoquent des préoccupations concernant les violations de droits d’auteur et l’utilisation de leur contenu pour entraîner des modèles d’IA qui pourraient ensuite les concurrencer. D’autres s’inquiètent de la possibilité que les systèmes d’IA imitent ou reproduisent étroitement leur contenu, ce qui pourrait réduire le trafic vers leurs propres sites.
Il existe également des préoccupations plus larges d’ordre philosophique et éthique concernant le consentement et la compensation dans l’utilisation des contenus Web pour la formation de l’IA. Beaucoup estiment que les sites Web devraient avoir plus de contrôle sur l’utilisation de leurs données, en particulier par les entreprises d’IA à but lucratif.
Cependant, le blocage des crawlers n’est pas sans inconvénients potentiels pour les sites Web. À mesure que les outils de recherche et de découverte alimentés par l’IA deviennent plus répandus, les sites qui bloquent ces crawlers pourraient se retrouver moins visibles ou accessibles par ces nouveaux canaux. Cela crée un dilemme pour les éditeurs Web cherchant à protéger leur contenu tout en maintenant leur visibilité.
Paysage juridique incertain
Le paysage juridique entourant le scraping de sites Web et l’utilisation des données de formation pour l’IA reste incertain. Alors qu’une affaire de 2019 entre LinkedIn et HiQ Labs a confirmé la légalité générale du scraping de sites Web accessibles au public, des poursuites en cours contre OpenAI et d’autres entreprises d’IA remettent en question certains aspects de cette pratique.
L’étude d’Originality.AI a également révélé des schémas intéressants dans la manière dont différents types de sites Web abordent le blocage des crawlers. Les sites de commerce électronique, par exemple, montrent des réponses variées, certains comme Amazon mettant en place des blocages tandis que d’autres restent ouverts. Les institutions éducatives et de recherche permettent généralement la plupart des crawlers, tandis que les sites de nouvelles et de médias tendent à être plus restrictifs.
Cette tendance à l’augmentation des blocages de crawlers représente un changement significatif dans la relation entre les éditeurs Web et les entreprises d’IA. Elle met en lumière les tensions croissantes autour de la propriété des données, de la vie privée et de l’avenir de la création de contenu dans un monde de plus en plus dominé par l’IA. À mesure que les technologies d’IA continuent de progresser rapidement, ces questions resteront probablement au premier plan des discussions sur la gouvernance d’Internet, les droits numériques et l’économie du contenu en ligne.
Pour les utilisateurs d’Internet, les implications de cette tendance ne sont pas encore claires. À court terme, elle pourrait entraîner des incohérences dans la capacité des systèmes d’IA à fournir des informations provenant de certaines sources. À long terme, elle pourrait influencer les types de services d’IA qui se développent et leur mode de fonctionnement.
Alors que cette situation continue d’évoluer, il sera crucial pour les décideurs politiques, les entreprises technologiques et les créateurs de contenu de s’engager dans un dialogue continu sur l’équilibre entre l’innovation et les droits de confidentialité et de propriété à l’ère numérique. La vague actuelle de blocages de crawlers pourrait n’être que le premier mouvement d’un processus plus long de négociation et d’adaptation entre les éditeurs Web et les développeurs d’IA.





