



John Mueller, analyste senior chez Google, a récemment apporté des éclaircissements sur une question déroutante rencontrée par les webmasters : l’indexation des pages bloquées par robots.txt. Cette explication est venue en réponse à une question posée par Rick Horst, un professionnel du SEO, sur LinkedIn. La discussion a mis en lumière la manière dont Google gère ces pages et a offert des informations précieuses aux propriétaires de sites web et aux praticiens du SEO.
Comprendre le problème de base
Rick Horst a décrit une situation où :
- Des bots généraient des backlinks vers des URL de paramètres de requête (?q=[requête]) inexistantes sur le site web.
- Ces pages étaient bloquées dans le fichier robots.txt.
- Les pages avaient également une balise « noindex ».
- Google Search Console montrait ces pages comme « Indexées, bien que bloquées par robots.txt ».
La question centrale était : pourquoi Google indexerait-il des pages alors qu’il ne peut même pas voir le contenu, et quel avantage cela pourrait-il avoir ?
L’explication de John Mueller
Mueller a fourni une réponse détaillée, en décomposant plusieurs points clés :
Robots.txt vs. Noindex
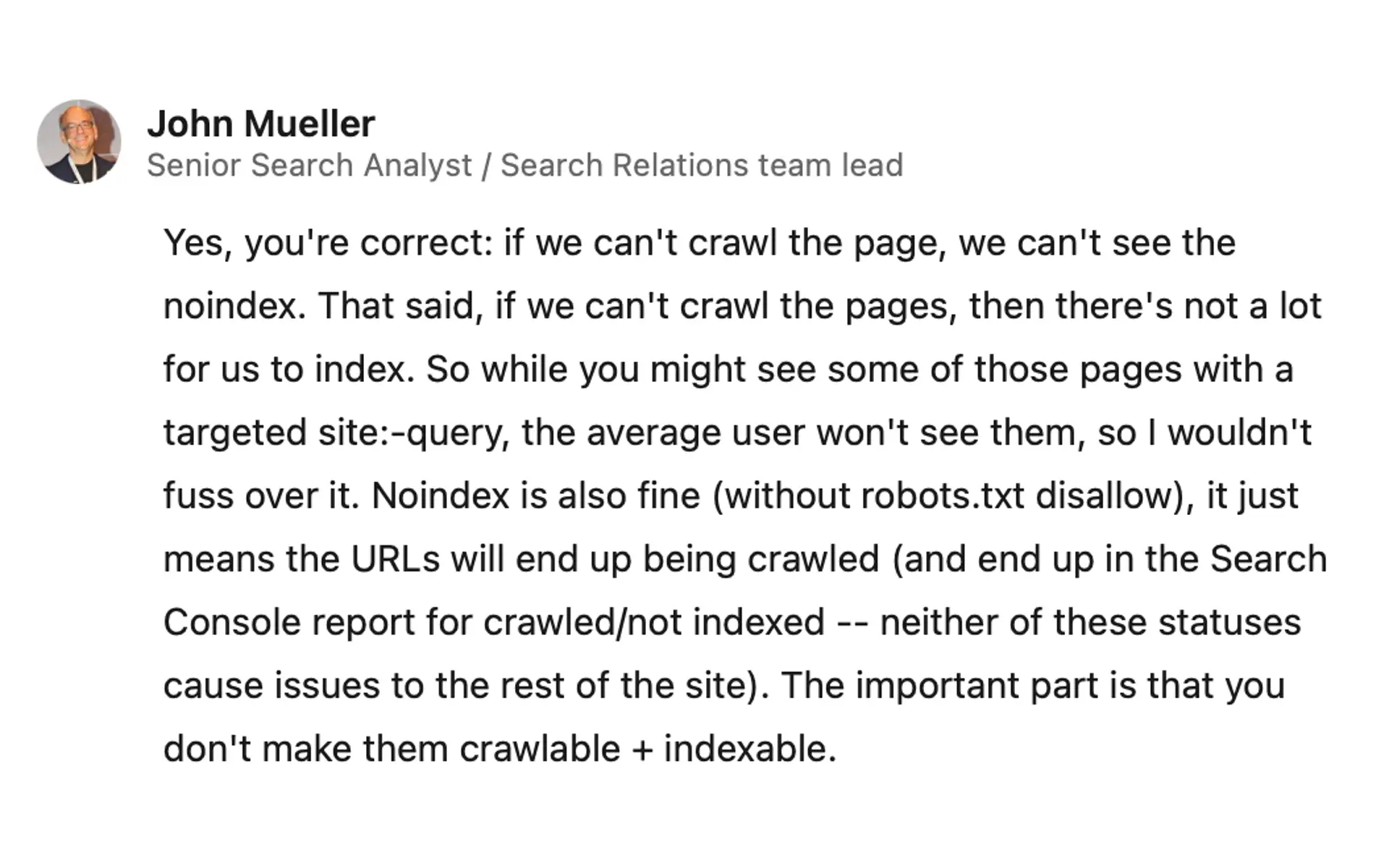
Mueller a confirmé que si Google ne peut pas explorer une page en raison des restrictions de robots.txt, il ne peut pas non plus voir la balise noindex. Cela explique pourquoi les pages bloquées par robots.txt mais contenant une balise noindex pourraient tout de même être indexées.
Indexation limitée
Mueller a souligné que si Google ne peut pas explorer les pages, il n’y a pas beaucoup de contenu à indexer. Il a déclaré : « Bien que vous puissiez voir certaines de ces pages avec une requête site:-ciblée, l’utilisateur moyen ne les verra pas, donc je ne m’inquiéterais pas pour cela. »
Noindex sans blocage de robots.txt
Mueller a expliqué que l’utilisation de noindex sans blocage de robots.txt est acceptable. Dans ce cas, les URL seront explorées mais finiront dans le rapport Search Console « explorées/non indexées ». Il a assuré qu’aucun de ces statuts ne cause de problèmes pour le reste du site.
Importance de l’explorabilité et de l’indexabilité
Mueller a insisté sur le fait qu’il est important de ne pas rendre les pages à la fois explorables et indexables.
Robots.txt en tant que contrôle d’exploration
Dans un commentaire de suivi, Mueller a clarifié que robots.txt est un contrôle d’exploration, pas un contrôle d’indexation. Il a déclaré : « Le robots.txt n’est pas une suggestion, c’est aussi absolu que possible (c’est-à-dire, si c’est analysable, ces directives seront suivies). » Il a également reconnu que ce genre de situation abusive avec des formulaires de recherche est courant et a conseillé de laisser les pages bloquées par robots.txt, en suggérant que cela ne pose généralement pas de problème.
Implications pour les webmasters et les professionnels du SEO
Les explications de Mueller ont plusieurs implications importantes :
Limitations de robots.txt
Bien que robots.txt puisse empêcher l’exploration, il ne prévient pas nécessairement l’indexation, surtout s’il y a des liens externes vers la page.
Efficacité des balises noindex
Pour que la balise noindex soit efficace, Google doit pouvoir explorer la page. Bloquer une page avec robots.txt tout en utilisant une balise noindex est contre-productif.
Gestion des URL générées par les bots
Pour les sites web confrontés à des problèmes d’URL générées par des bots, utiliser robots.txt pour bloquer ces pages est généralement suffisant et ne causera pas de problèmes pour le reste du site.
Rapports Search Console
Les webmasters doivent être conscients que les pages bloquées par robots.txt peuvent tout de même apparaître dans certains rapports de la Search Console, mais cela n’indique pas nécessairement un problème.
Équilibrer le contrôle de l’exploration et de l’indexation
Les propriétaires de sites web doivent considérer attentivement leur stratégie pour contrôler l’exploration et l’indexation, en comprenant que ces processus sont distincts dans le système de Google.
Principales conclusions
- Robots.txt bloque l’exploration mais ne garantit pas la prévention de l’indexation.
- Les balises noindex sont efficaces seulement si Google peut explorer la page.
- Pour une exclusion complète des résultats de recherche, permettez l’exploration mais utilisez noindex.
- Les URL générées par des bots peuvent souvent être bloquées en toute sécurité avec robots.txt.
- Google peut indexer des pages non explorées en se basant sur des informations de liens externes.





